시작하며
쿠버네티스에서 서비스메쉬 솔루션으로 Istio를 운영하다보면 Pod가 종료될 때 커넥션이 비정상적으로 종료되는 경우가 종종 발생할 수 있다.
Pod가 종료되는 경우는 kubectl delete를 통해 직접 Pod를 죽이는 경우, 롤링 업데이트나 스케일 인을 진행하는 경우 등 다양하다.
커넥션이 비정상적으로 종료되는 이유는 무엇일까?
다양한 경우의 수가 있을 수 있겠지만 아마 대부분 사이드카로 뜨는 istio-proxy 컨테이너가 애플리케이션 컨테이너보다 먼저 종료되는 것이
원인일 것이라고 생각한다.
v1.12 이전의 Istio를 이용하던 사람들은 다음과 같이 istio-proxy 컨테이너에 preStop 설정을 추가해 해당 컨테이너에 커넥션이 모두
종료된 후 istio-proxy 컨테이너가 종료되도록 하곤했다.
| |
심지어는 이렇게 매번 preStop을 설정해주는 것이 번거롭다보니 preStop을 자동으로 설정해주는 mutating webhook을 만들어 이용하기도 했다.
하지만 다행히도 v1.12부터는 이런 불편을 해소해줄 수 있는 EXIT_ON_ZERO_ACTIVE_CONNECTIONS라는 설정이 추가되었다.
이번 글에서는 EXIT_ON_ZERO_ACTIVE_CONNECTIONS를 설정하지 않는 경우 어떤 에러가 발생할 수 있는지, EXIT_ON_ZERO_ACTIVE_CONNECTIONS을 설정하면
정말로 Pod 종료 시 커넥션이 안전하게 종료되는지에 대해 정리해보려한다.
문제 상황
- Pod가 종료되기 시작하면
istio-proxy컨테이너는SIGTERM시그널을 받고 envoy proxy는 더 이상의 새로운 커넥션을 생성하지 않고 5초 뒤 종료된다.- 5초는 envoy proxy의 draining duration의 기본값이다.
- 우리는
SIGTERM이전에 형성되어있던 커넥션이 모두 정상 종료될 때까지 기다린 뒤 Pod가 안전하게 제거되길 기대한다. 3.하지만 만약SIGTERM이후 envoy proxy가 종료되는 5초 내에 커넥션이 정상 종료되지 못하면 커넥션은 끊어져버리게 된다.
즉 envoy proxy의 draining duration보다 내에 커넥션을 정상 종료하지 못하는 처리 시간이 긴 요청들이 취약한 상황이다.
해결 방법
앞서 잠깐 언급했듯이 Istio v1.12부터는 이 문제를 해결할 수 있는 EXIT_ON_ZERO_ACTIVE_CONNECTIONS 라는 설정이 추가되었다. 이는 1.12 Change Notes에서
관련 내용을 찾아볼 수 있었다. pilot-agent 커맨드 문서에서도 관련 내용을 찾아볼 수 있다.
그 외에 MINIMUM_DRAIN_DURATION 라는 설정도 존재하는데 이것이 앞에서 말한 envoy proxy의 draining duration이다.
EXIT_ON_ZERO_ACTIVE_CONNECTIONS를 활성화하지 않으면 envoy proxy는 MINIMUM_DRAIN_DURATION 경과 후 종료되겠지만 EXIT_ON_ZERO_ACTIVE_CONNECTIONS를 활성화함으로써
envoy proxy가 커넥션이 모두 종료될 때까지 기다린 후 종료되도록 할 수 있다. 이 경우 애플리케이션이 해당 커넥션을 통한 요청에 대한 처리를 하던 중 envoy proxy가 먼저 죽어버려 커넥션이
끊기는 에러 케이스를 방지할 수 있을 것이다.
해결 방법 적용해보기
해결 방법을 적용해보기위해 해결 방법을 적용해볼 환경은 다음과 같다.
| Name | Description |
|---|---|
| Kubernetes | GKE 1.24.7 |
| Istio | 1.16.0 |
| Domain name | graceful-shutdown-app.jinsu.me |
| Application server deployment name | graceful-shutdown-app |
| Container image | kennethreitz/httpbin |
* 테스트에서는 여건 상 편의를 위해 Istio 1.12 버전이 아닌 1.16 버전을 사용했다.
kennethreitz/httpbin 이미지는 간단한 http 서버가 필요할 때 유용하게 사용할 수 있다.
/delay/:seconds라는 엔드포인트는 GET 요청이 들어올 경우 :seconds만큼의 딜레이 후 응답한다. 이를 통해
처리 시간이 긴 애플리케이션을 흉내내어 EXIT_ON_ZERO_ACTIVE_CONNECTIONS 라는 해결 방법이 올바르게 동작하는지 확인해볼 수 있을 것이다.
우선 EXIT_ON_ZERO_ACTIVE_CONNECTIONS을 설정하지 않은 경우 필자가 언급한 것과 같이
요청을 보내고 Pod를 종료시킬 때 duration seconds(5s by default) 안에 응답이 완료되지 않으면
정말 커넥션 에러가 발생하는지 살펴보겠다.
| |
graceful-shutdown-app Deployment를 애플리케이션 서버 역할이라고 가정하자.
애플리케이션 서버는 요청 접수 후 10초의 딜레이 후 응답하는 게 정상이겠지만 위와 같이 모든 Pod이 SIGTERM을 수신한지 약 5초만에 503이라는 응답을 얻게 됐다.
이는 애플리케이션의 사이드카에 떠있는 envoy가 약 5초만에 죽어 커넥션이 끊겼기 때문이다.
* 자세한 내용) 커넥션이 끊겼는데 connection reset 이런 에러가 아닌 503 에러 응답을 받은 이유는 istio-ingressgateway <-> graceful-shutdown-app Pod 간의 커넥션에서 istio-ingressgateway가 connection reset 에러를 받고서는 클라이언트(필자)에게 알아서 503으로 응답을 내려주기 때문이다. 관련된 내용은 istio-ingressgatway Pod의 로그 레벨을 debug로 낮춘 뒤 확인할 수 있다. 로그 예시는 다음과 같다.
| |
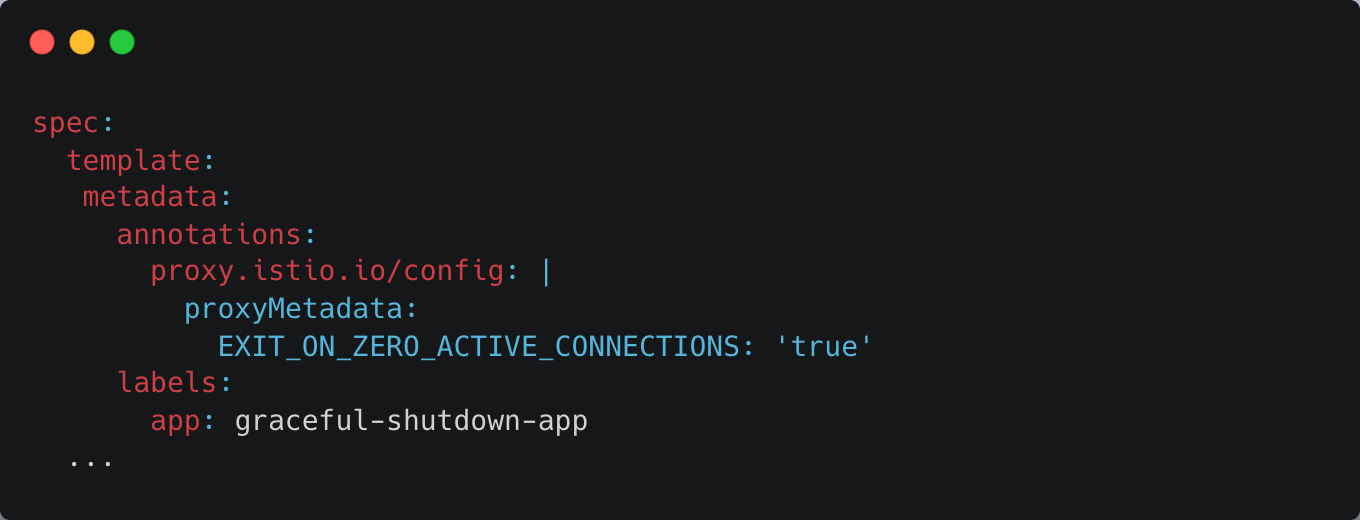
자! 그럼 드디어 EXIT_ON_ZERO_ACTIVE_CONNECTIONS 을 설정해보겠다. Deployment의 pod template을 통해 pod에 다음과 같은 annotation이 달리도록 설정해준다.
| |
Deployment의 pod template 수정으로 인해 새로 생성된 Pod들은 Istio의 mutating webhook에 의해 EXIT_ON_ZERO_ACTIVE_CONNECTIONS=true라는 환경변수를 갖게 된다.
그로 인해 SIGTERM을 받은 후 active connection이 없어질 때까지 기다린 뒤에서야 envoy가 종료되며 다음 예시와 같이 클라이언트들은 Pod 종료와 무관하게 항상 올바른 응답을 받을 수 있다.
| |
주의사항) 애플리케이션 서버의 커넥션을 성공적으로 종료하는 데에 Pod의 terminationGracePeriodSeconds 보다 오랜 시간이 필요한 경우에는
EXIT_ON_ZERO_ACTIVE_CONNECTIONS 을 설정해주었다 하더라도 terminationGracePeriodSeconds 이후 커넥션이 끊어지는 에러를
겪게 될 수 있다. SIGTERM 을 보내고 terminationGracePeriodSeconds 후에도 종료되지 않은 컨테이너는 SIGKILL을 통해 강제로 종료해버리기 때문이다.
따라서 이런 경우엔 terminationGracePeriodSeconds를 좀 더 큰 값으로 설정해줘야할 것이다. 기본값은 현재 기준으로 30s이다.
(참고로 kennethreitz/httpbin 이미지는 max delay duration이 아마 10s로 개발되었을 것이라 이 kennethreitz/httpbin 이미지로 이런 케이스를 테스트해보려면 terminationGracePeriodSeconds를 7초 정도로 설정해야 할 것이다.)
마치며
이번 글에서 설명한 EXIT_ON_ZERO_ACTIVE_CONNECTIONS 또한 필수 기능 같지만 1.12 버전 이전에는 지원되지 않았다.
사소한 기능처럼 느껴질 수 있지만 실제로는 수많은 사람들의 불편을 덜어줄 수 있는 아주 편리한 기능이라고 생각한다. 이 기능이 개발될 수 있도록 해당 이슈에서 열심히 활동해준
엔지니어들에게 감사 인사를 전한다. 나도 내년쯤엔 그들처럼 거대한 오픈소스 프로젝트에 좋은 영향을 줄 수 있는 글로벌한 엔지니어가 될 수 있을까?!