시작하며
얼마 전 Channel use case 라는 Go에서의 채널 사용에 관한 글을 하나 읽었다. 한 동안 스프링 업무 보느라 잊고 지냈던 Go의 concurrency pattern이나 channel의 쓰임에 대해 다시 한 번 고민해볼 기회가 되었다. 항상 어떤 기술이 왜 좋은지, 언제 써야할지를 많이 고민하는 편이라 그 실제적인 유즈 케이스에도 굉장히 관심이 많은 편이다. 해당 글의 아쉬움은 제목은 use case였음에도 구체적인 use case라기 보다는 코드 예시 같은 느낌이 컸다.
아쉬움이 좀 있었던 터라 개인적으로 지인과 얘기해보며 고민을 좀 더 해보았다. 그 결과 channel을 세마포어처럼 이용해서 동시작업 속도를 조절해야하는 경우에 사용하면 좋을 것 같다는 생각이 들었다. 그리고 그 실제적인 예시로는 게시물의 조회수 관리가 될 것 같다.
운영체제를 비롯한 기타 수업에서 배우는 정형화된 내용 같은 것이 아니라 제 개인적인 생각을 적어보는 것이라 틀린 내용이 있을 수도 있으니 자유롭게 의견 공유해주시면 감사드리겠습니다.
이번에 다룰 Concurrency pattern… 언제 쓰면 좋은 것이냐 도대체..!
이번 글에서는 “channel을 통해 세마포어처럼 작업 속도 혹은 리소스 양을 제한하는 Concurrency pattern“에 대해 다뤄볼 것이다. 이 패턴이 도움될 수 있는 상황의 특징은 다음과 같다고 생각한다. 이는 주로 메시징 서비스를 이용하는 경우나 channel을 바탕으로 semaphore 기능을 이용하지 않고 제한 없이 goroutine을 만드는 경우와 비교했을 때를 기준으로 한다.
- 수행되지 못해도 크게 상관은 없는 경우 - channel은 기본적으로 메모리를 이용하기 때문에 어떠한 channel을 통해 대기 중인 데이터는 프로세스가 죽으면 날아갈 수 있다. 이 경우는 application 내부 level의 동기화 큐 같은 channel을 이용할 것이 아니라 외부 서비스 레벨의 고가용성 큐를 이용하는 것이 더 적절하다.
- 동기화가 보장되면 좋은 경우 - channel은 너무나도 편리한 동기화 기능을 제공한다! 이건 반박이 불가능하다. ㅎㅎ 하지만 1번과 마찬가지로 서비스를 clustered 시스템으로 운영할 경우는 channel을 이용해 동기화할 것이 아니라 외부의 큐나 기타 메시지 서비스를 이용하는 것이 적절하다. (channel은 기본적으로 동기화를 아주 편리하게 제공하지만 clustered 혹은 distributed 시스템인 경우 여러 instance나 process 사이의 동기화는 channel로 수행할 것이 아니라 외부 메시징 시스템 같은 것이 필요하다는 의미.)
그렇다면 수행되지 못해도 크게 상관은 없으면서 동기화가 보장되면 좋은 경우는 어떤 경우일까? 나는 게시글의 조회수 증가 기능을 생각해보았다.
유즈케이스 예시 - 게시글의 조회수 증가 기능
조회수 증가는 수행되지 못해도 크게 상관은 없다.
조회수는 돈이 오가는 서비스나 투표 집계 서비스 같은 것이 아니고 부가적인 기능이기 때문에 수행되지 못해도 크게 상관은 없다. real-time 성격의 작업이 아니기 때문에 급증한 요청은 메모리에서 대기시킨다. 만약 대기 중에 프로세스가 죽는다면 조회수 증가 요청 chan에서 대기 중이던 요청은 유실된다. 모든 기술은 trade-off이다.
만약 꼭 수행되어야하는 작업이라면 channel을 이용한 concurrency pattern을 이용할 것이 아니라 다음과 같이 작업하는 것이 좋을 수 있다.
channel을 통해 fan-in fan-out하거나 요청을 주고 받을 것이 아니라 고가용성의 외부 메시징 시스템(e.g kafka, sqs)을 이용한다. 하지만 이 경우 하나의 go process 내에서 channel을 통해 데이터를 주고 받을 때보다 느리고 번거롭다는 단점이 존재한다!
동시적 요청 spike 시에도 조회수를 바로 바로 처리하면서 메모리에 대기될 요청이 없게 한다. 하지만 이 경우 real-time 성격이 아닌 조회수 증가 작업 또한 바로 바로 처리하면서 DB 부하는 더 커질 것이고, 좀 더 real-time 성격인 실제 조회(사용자가 게시물을 전달받는 것) 작업이 더욱 지연될 수도 있다.
예를 들어 10명이 동시에 요청하면서 오버헤드가 증가한 편이지만 조회수 처리 작업은 나중에 하고 일단은 10명의 요청을 신속히 응답하는 것이 아니라 가뜩이나 오버헤드가 증가하는데 조회수도 바로 바로 수정(+1)하다보니 더 오버헤드가 커져 사용자는 더 증가된 latency를 경험하게 된다.
동시적 조회 요청 발생 시 조회수 증가 작업은 동기화가 보장되는 것이 좋다.
만약 한 게시물에 대해 10개의 동시적인 조회 요청이 발생했고, 각 요청은 게시글의 조회수를 1씩 증가시킨다고 할 때, 동기화가 보장되지 않으면 모두가 (기존 조회수 + 1) 작업을 수행해 결과적으로 조회는 10번 했지만 조회수는 1만 증가하게 될 수 있다.
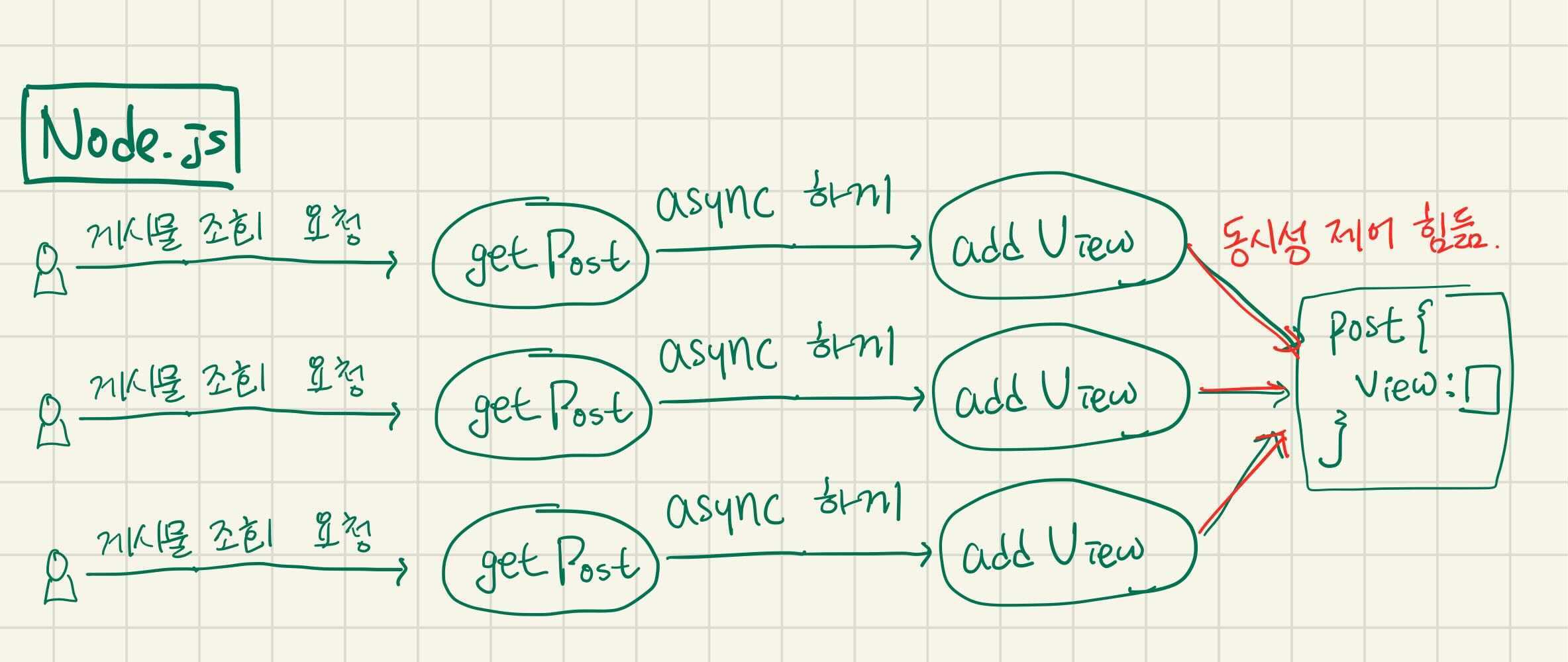
동시성 제어에서 Node.js의 한계 예시 - 동시적 조회 시 동시적 조회수 증가 작업을 제어하기 힘듦.
제가 Node.js를 공부한 게 몇 년 되어서 쉽게 가능한데 제가 모르는 걸 수도 있습니다… EventEmitter라는 게 있는 것 같긴한데, 엄청 편해보이진 않네요….

| |
일반적으로 Nodejs에서 수행하는 async 방식을 이용하는 예시를 보면 위과 같다. 실제로는 DB에 대해 작업하는 경우가 많겠지만 예시는 간단히 메모리에서 수행했다. Nodejs가 async한 작업을 수행, 관리하기 편한 편이지만 이런 경우 addViewAsync() 작업들만을 동기화시킬 수 있는 방법이 없다(없는 건 아니겠지만.. 힘들 듯!). 그렇기 때문에 동시적인 조회 발생 시 +1 작업을 동기화 시킬 수 없고 결과적으로는 새로운 조회수가 (동시적 요청 전 조회수 + 1)가 되어버리는 오류가 발생할 수 있다.
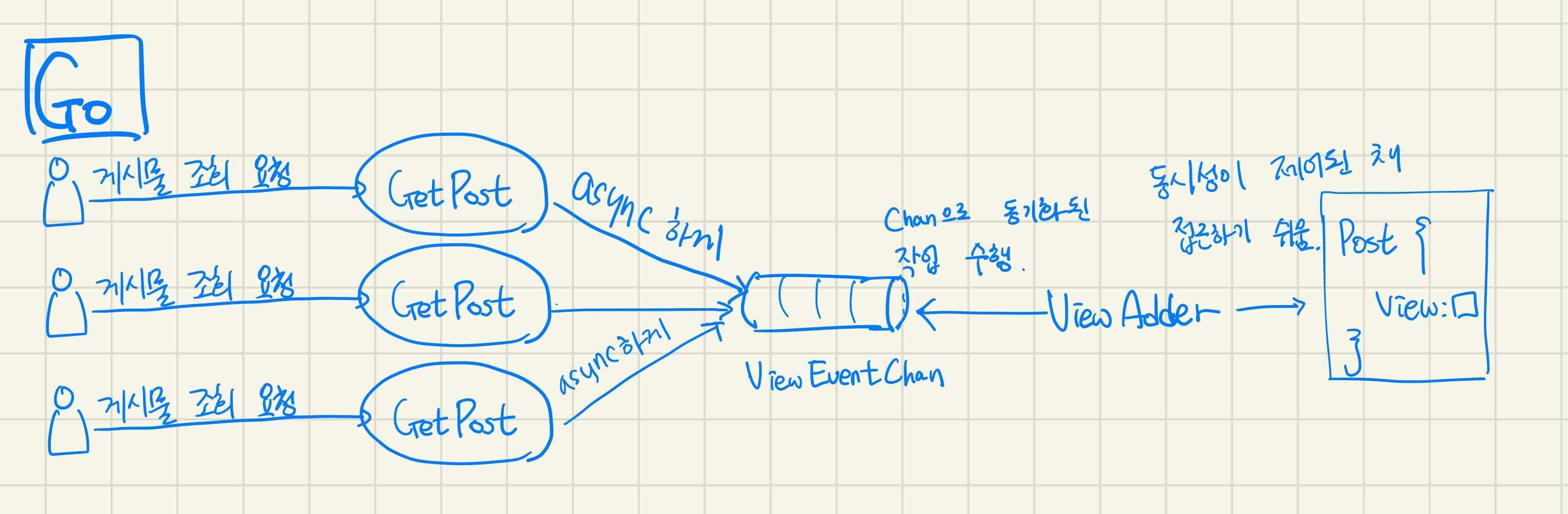
Goroutine과 Channel을 이용해 간단히 동시성 제어 - chan에 조회수를 증가할 게시물을 전달해 동기화하여 작업
| |
반면 Go에서는 위와 같이 channel과 goroutine을 이용해 효과적으로 조회수 증가 작업의 속도를 제어하거나 동기화시킬 수 있다. 조회수 증가 요청을 담는 chan에 게시물의 데이터를 전달하는 작업은 async하게 진행하고 GetPost(id)는 Post를 바로 리턴한다.
이 경우 직접 ViewEventChan을 통해 데이터를 처리하는 goroutine들이 알아서 조회수 증가 작업은 비교적 동기화된 방식으로 진행해준다! 만약 ViewEventChan의 데이터를 처리하는 goroutine을 1개만 띄워놓으면 single instance, single process 환경에서는 완벽히 동기화해서 작업을 처리할 수 있다. 만약 goroutine을 N개, 예를 들어 2개 띄운다면 동시적 요청이 10개 발생했다쳐도 10개의 조회수 증가 처리가 동시적으로 수행되는 게 아니라 2개씩 처리되기 때문에 요청 Spike 시 어느 정도 작업 속도를 제한함으로써 동시성으로 인한 오류를 어느 정도 줄일 수 있다.
심화) 동기화는 조금 양보하고 Goroutine을 scale out하기
| |
앞서 말했듯이 기술은 항상 trade-off이다. 한 goroutine을 이용해 조회수 증가 작업을 전적으로 동기화시켜서 진행하려다보니 spike 시에 너무 chan(메모리)에 대기하는 데이터가 많아질 수 있고 이렇게 대기되는 요청은 프로세스가 죽어버리면 함께 증발할 수 있다. 그렇기 때문에 만약 일정 시간 이상 동안 조회수 증가 요청이 대기해야한다면 작업 처리 goroutine을 더 증가시키는 것도 하나의 방법이 될 수 있다. 하지만 이런 방식은 꽤나 복잡하기 때문에 요청이 상당히 불규칙하고, 심화된 서비스를 제공하는 기업이 아니라면 그냥 단순하게 이용하는 것이 더 좋다고 생각된다. Go는 Simple한 언어이기 떄문에…! 만약 그런 복잡한 작업을 할 것이라면 앞서 말했듯 외부에 메시징 서비스를 두고 일종의 batch나 worker 형태로 구성하는 것이 좋을 것 같다.
마치며
한 동안 스프링 개발하느라 바빴는데 오랜만에 Go를 통해 고뇌하니 리프레시가 됐던 것 같다. 작년 같았으면 앞서 소개했던 Channel use case 같은 글을 읽으면서 이해하지 못한 내용이 많았을텐데, ‘이제는 거의 다 사용해보긴 했던 패턴이네’ 정도의 느낌이었어서 어떻게 보면 뿌듯하기도 했지만, ‘패턴을 짤 수는 있는데 그래서 진짜 어디다 써야하는 거지? ㅋㅋㅋ….’ 싶은 고민이 들었다. 다행히 한 가지 실존할만한 유즈케이스를 찾은 것 같아 좋았고, 그 케이스에 대해 이렇게 글을 써보았다. 하나 걱정인 것은 “수행되지 못해도 크게 상관은 없는 경우 본 글과 같은 패턴을 이용하면 좋다.“고 설명한 부분에서 ‘channel을 이용하면 작업이 유실될 수 있다는 건가?’ 라는 오해에 빠져들 수 있을 것 같다는 점이다. 내가 말하고 싶었던 부분은 프로세스 내부에서의 작업 유실이 아니라 프로세스 자체가 죽어서 메모리의 대기 중인 요청이 날아가는 경우가 아닌 프로세스의 생명과도 무관하게 언젠가 꼭 수행되어야하는 작업과 비교했을 땐 channel보다는 외부 메시징 서비스를 이용하는 것이 좋다는 의미였다. 하지만 이러한 내용을 잘 전달하기 쉽지 않았던 것 같다. ㅜㅜ
옛날엔 기술을 잘 가져다 쓰게 사용법을 잘 써놓은 글들도 즐겨 봤던 것 같은데, 요즘엔 개인적으로 이런 기술 자체를 다루는 글보다 어떤 경우에 써봤더니 어떤 장단점이 있더라 이런 글들이 더 끌리는 것 같다! (’그래서 저도 이번에 하나 써봤습니다 ㅎㅎ’)
부록 - 게시물에 조회수 필드를 두는 이유
보통은 조회수 자체만을 이용하기 보다는 게시물 - 유저간의 “조회"라는 관계를 정의하는 테이블을 하나 더 두기 마련이다. 그래야 어떤 유저가 최근에 무엇을 조회했는지도 알 수 있고, 중복 조회수 증가를 막을 수 있기 때문이다. 그리고 이렇게 조회 관계 테이블을 두면 group by를 통해 게시물 조회 API 제공 시에 조회수를 계산해 제공할 수 있다. 하지만 이런 식으로 조회수를 제공하면 매번 DB query를 너무 많이 수행해야한다는 단점이 있다. 따라서 조회수만 필요할 때에는 게시물의 조회수 필드를 이용하고, 이 유저가 최근에 무엇을 조회했는지, 이 유저가 이 글을 조회한 적이 있는지를 체크할 때에는 게시물 조회 관계 테이블을 이용하는 것이 좋다. 이와 관련된 내용으로 약 두 달 전에도 온라인 상에서 얘기를 나눠본 적이 있다.
참고: PHP, MySQL: 좋아요 기능 만들기 - http://yoonbumtae.com/?p=3287
참고 자료
이번엔 특별히 참고한 자료가 많이 없습니다. 이번엔 그냥 저의 Go에 대한 고뇌를 바탕으로 작성했습니다.