Go 언어로 적용해보는 Computer Science의 첫 번째 내용으로 OS 관련 내용 중 이론적으로는 흔하게 접할 수 있지만 실제 적용에 대한 내용은
찾아보기 힘들었던 Mutex, Semaphore에 대해 알아보려한다.
Mutex와 Semaphore은 각각의 추상적인 개념을 바탕으로 OS나 Go 등에서 사용될 수 있기에 세부적인 내용은 문맥에 따라 달라질 수 있다고 생각한다. 예를 들어 Go에서의 Mutex는 주로 sync.Mutex를 이용한 서로 다른 Goroutine의 동시 접근에 대한 제어를 의미하는 반면, 다른 프로그래밍 언어나 OS에서는 주로 서로 다른 Kernel thread나 Process에 대한 동시 접근 제어를 의미할 수 있다.
Mutex
Mutex는 Mutual Exclusion의 줄임말로 상호 배제를 의미한다. 즉 서로 다른 워커가 공유 자원에 접근하는 것을 제한한다는 말이다. Go에서는 이 “워커“가 Goroutine이 되고, 컨텍스트에 따라 프로세스가 될 수도, 스레드가 될 수도 그 외의 다른 존재가 될 수도 있다. 공유 자원이란 여러 워커가 동시에 접근하는 자원을 말하고 이 공유 자원에 대한 동시 접근을 제한해 thread-safe하게 작업하고자 하는 영역을 Critical section이라고 한다. Cricical section은 Mutex가 Lock을 수행한 뒤 Unlock되기 전까지의 영역이며, Lock과 Unlock은 Atomic한 작업이기때문에 어떠한 경우에도 동시적으로 수행될 수 없다.
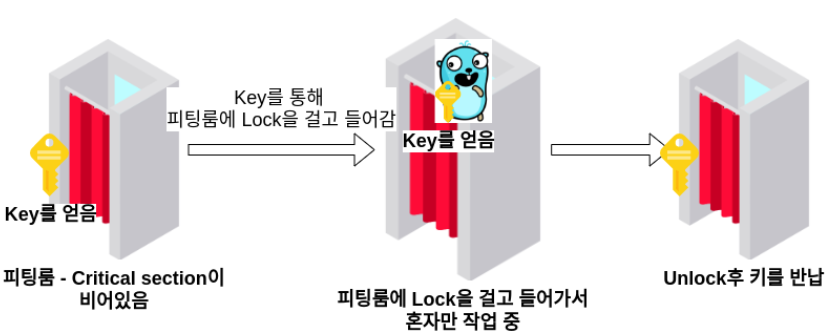
이해하기 쉽게 예시를 통해 접근해보겠다. 원래 화장실 예제를 보고 굉장히 와닿았는데, 화장실보다는 피팅룸이 좀 더 청결한 것 같아서 피팅룸으로 예를 들어보겠다. 우리 귀여운 고퍼가 피팅룸을 한 개만 운영하는 옷가게에 방문했다고 가정해보자.

- 피팅룸 - Critical section
- 고퍼가 피팅룸에 들어가서 옷을 입는 작업은 하나의 Goroutine
동시에 여러 고퍼가 하나의 피팅룸에서 옷을 갈아입으려한다면 😟 난처한 상황이 발생할 것이다. 그렇기때문에 피팅룸에는 Lock, Unlock 기능이 존재해야하는데, 이 기능을 구현한다해도 Atomic하게 동작할 수 있도록 제대로 구현하지 않는다면 한 워커가 Lock을 하는 사이에 다른 워커가 동시에 Lock을 걸려할 수 있고, 그 경우 두 워커가 동시에 한 피팅룸(Critical Section)에서 작업을 하려할 것이다. 그렇기때문에 Lock, Unlock은 Atomic해야하며 이렇게 각 워커를 상호 배제시켜 동시에 작업할 수 없도록 하는 것이 바로 Mutex이다.
Mutex를 이용한 Go program - Counter
Count = 0에서 시작해 동시적으로 +1을 10만 번, -1을 10만 번 수행하는 카운터 프로그램
그럼 실생활에 비유한 Mutex는 이 정도로 마치고, Mutex가 어떻게 사용되는지 Go로 짠 간단한 Counter 프로그램을 통해 알아보자.
- Mutex를 잘 적용한 경우 - 몇 번을 수행하든 결과는 0.
- Mutex가 적용되지 않은 safe하지 않은 경우 - 결과가 0이 나오지 않을 수 있다.
특히 Go에서는 sync 패키지의 Mutex라는 type을 통해 간단하게 Mutex 기능을 이용할 수 있다. 동일한 Mutex struct를 참조한다면 같은 Key를 이용한다는 개념이고, mutex.Lock()을 호출한 뒤 mutex.Unlock()이 호출되기 이전까지가 Critical section이 되며 다른 goroutine들은 같은 Mutex(즉 키)에 의한 Critical section에 진입할 수 없다.
내가 처음 Mutex를 처음 접했을 때 한 가지 헷갈렸던 것은 당시 Critical section이라는 개념이 없었기 때문에 Lock을 호출하기만 하면 런타임에 알아서 스마트하게 Lock과 Unlock사이의 변수들에 대한 접근 중 동시적인 접근만을 잠시 블락해주는 줄 알았는데, 사실 그 사이 변수들중 동시적으로 접근하려는 변수에 대해서만 잠시 블락해주는 게 아니라 Lock과 Unlock 사이를 Critical section으로 만드는 것이었다.
자 그럼 Count라는 하나의 int형 변수에 동시적으로 접근을 하는 상황을 극대화하기 위해 여러 고루틴으로 작업해보겠다. +1을 1만 번하는 고루틴을 10개, -1을 1만 번하는 고루틴을 마찬가지로 10개 이용하겠다.
전체 코드 참고: https://play.golang.org/p/xaLE1YkAdvd
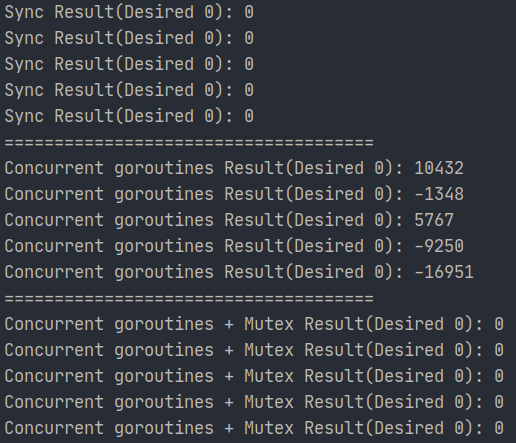
- 우리가 일반적으로 익숙한 Sync 즉 동기적인 순차적 진행 시에는 당연히 10만번 +1, 10만번 -1 후에 결과가 0이었다.
- 동시적 접근을 수행하자 10만번 +1, 10만번 -1을 했지만
Count += 1을 수행하던 중 또 다른Count += 1이 수행되는 등의 원치않던 상황이 야기될 수 있기에 결과값이 0인 경우를 찾기 힘들다. - 여러 Goroutine이 concurrent하게 진행하되
Count += 1,Count -= 1과 같은 동시적 접근이 수행되어서는 안되는 영역은 Critical Area로 설정해 상호 배제적으로 작업되게 하기 위해 Critical section의 전/후에sync.Mutex를 이용해 Lock, Unlock 기능을 넣어주자 기대했던 대로 0의 결과를 얻을 수 있었다.
💡 Mutex.. 그래서 언제 써요?
사실 Mutex라는 개념이 그렇게 어려운 것도 아니고, 사용법 자체가 어려운 것도 아니다. 나는 하지만 항상 “언제”, “왜” 써야하는지를 궁금해하는 편이다.
- Critical section에서 많은 시간이 소요되는 경우? ⇒ ❌ 위의 counter와 같은 작업은 대부분의 작업이 critical section 속에 있다고 볼 수 있다. 이 경우 동시적인 작업과 함께 Lock, Unlock을 하며 critical section을 관리하는 것보다 애초에 작업 자체를 동기적으로 수행하는 게 나을 수 있다. 왜냐하면 동시적 작업 속에서 Mutex를 통해 동기적으로 작업할 수 있도록 하는 것에서 오는 오버헤드는 분명히 존재하고, Critical section 밖에서 효율적으로 동시적으로 작업을 진행했다하더라도 critical section에서 병목이 발생해버려 전체적인 Throughput이 안 좋아질 것이다.
- Critical section에서는 적은 시간이 소요되고, 대부분은 동시적으로 작업이 가능한 경우? ⇒ ⭕ 예를 들어 어떤 API를 여러 번 호출한 뒤 그 응답 중 일부를 계속해서 더해 결과를 내는 Reduce 작업을 수행한다고 치자. 순차적으로 수행할 시 오랜 시간이 소요될 API 호출은 동시적으로 진행하고, 결과에 대한 Reduce 작업만 잠시 Critical section내에서 작업한다면 아주 좋은 성능과 함께 안전하게 작업할 수 있을 것이다!
Semaphore
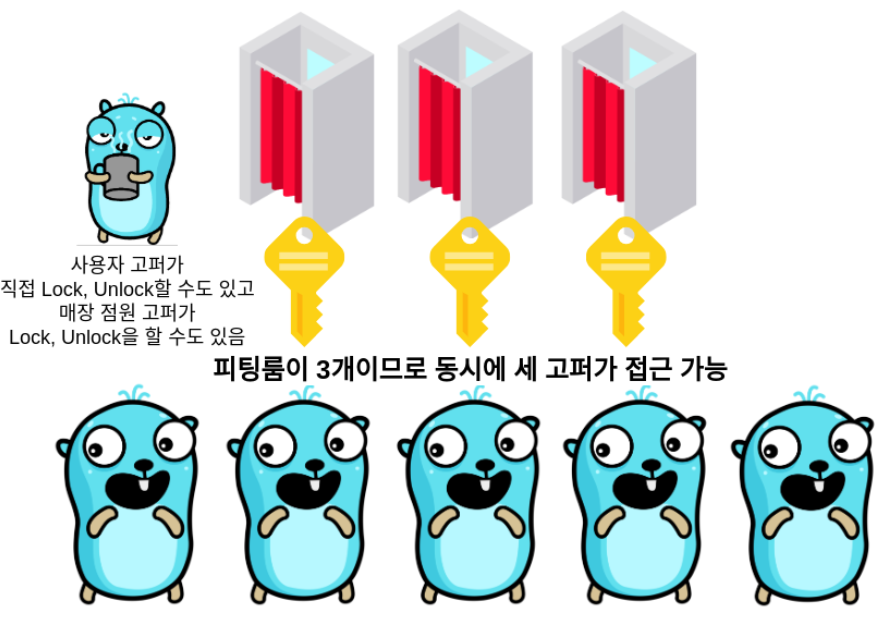
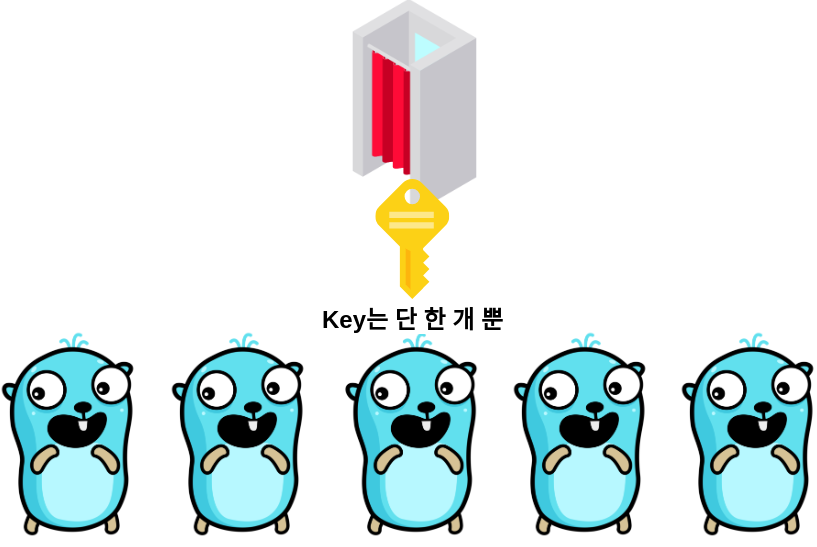
Mutex에서 대부분의 Lock이나 Critical section에 대한 내용을 설명했기 때문에 Semaphore에서 더 설명할 내용이 많지는 않다. Semaphore의 동작에 대한 간단한 예시는 위의 그림과 같은데, 5마리의 고퍼가 존재한다해도 동시에 접근할 수 있게하는 고퍼를 3개로 제한한다면 2마리의 고퍼는 피팅룸에 들어가지 못하고 블락된다. Locked와 Unlocked 상태 뿐인 Mutex와 달리 Semaphore는 임의의 개수를 세는 Counter처럼 동작해 임의의 개수의 워커만이 Critical section에 동시적으로 접근할 수 있도록 한다.
Counter를 예로 들자면 10개의 워커가 존재한다해도 “5"를 세는 Semaphore는 한 워커가 Critical section에 진입할 때마다 Counter 값을 1씩 낮추고, Critical section을 탈출할 때마다 Counter 값을 다시 1씩 높인다. 만약 어떤 워커가 Critical section에 진입하려는데 Count 값이 0이라면 초기에 계획했던 대로 5개의 워커가 이미 동시적으로 작업중이라는 의미이므로 이 워커는 한 워커가 Critical section을 나오면서 Counter 값을 다시 1 증가시킬 때까지 Block된다.
Mutex의 Lock과 Unlock이 Atomic하기에 어떠한 경우에도 동시적으로 수행될 수 없었듯이 Semaphore의 Counting 작업 또한 Atomic해야하고 그래야만 Thread-safe한 counter로 동작할 수 있다. Semaphore가 수행하는 Counting 작업은 주로 try를 뜻하는 네덜란드어 Proberen의 앞 글자를 딴 P와 increment를 뜻하는 Verhogen의 앞 글자를 딴 V로 두 가지가 표현하는 듯하다. P는 Count 값이 0이 아니면 작업을 수행하겠다는 의미하며 만약 Count 값이 0이라면 0이 아닌 값이 될 때까지 wait했다가 0 아닌 값이 되면 count 값을 1 감소시키며 작업을 시작한다. V는 작업을 마치며 count 값을 다시 1 증가시키겠다는 의미이다.
Mutex와 Binary semaphore의 유사한 점
동시 접근 워커를 1개로 제한하는 Semaphore의 경우 Count 값이 0과 1 두 개로만 존재할 수 있는데 이를 Binary semaphore라고한다. 특히 이는 Locked와 Unlocked라는 두 가지의 상태만을 갖는 Mutex와 유사하다. 하지만 Binary semaphore는 mutex가 유사한 기능을 할 뿐 동일하지는 않다는 의견이 많다. 그 이유는 Mutex는 Lock 방식을 이용하고 Semaphore는 Signal(신호) 방식을 이용하기 때문이다. Lock 방식의 경우 Lock을 수행한 워커만이 Unlock을 할 수 있는 반면 Signal 방식은 try(작업 시도)를 수행한 워커가 아니더라도 increment(작업 완료) 신호를 보낼 수 있기에 서로 명백히 동작 방식이 다르다는 것이다. (하지만 이 부분에 대해서는 직접 실습해보지는 못했다.)
*Semaphore를 이해하는 데에 있어 내가 착각해서 헤맸던 부분은 바로 Semaphore의 요점이 thread-safe한 count라고 착각*했던 것이다. 하지만 semaphore의 요점은 여러 워커에 대해서 thread safe한 count 기능을 제공하는 것이 아니라 임의의 숫자만큼의 동시적 접근을 허용하고, 그 이상은 Block 상태로 대기시킨다는 것이다.
Semaphore를 이용한 Go Program 1 - Counter
go에서 Semaphore를 이용하는 방법은 크게 2가지가 있는 것 같다. 아래 두 가지 방법 중 좀 더 Go스러운 channel을 이용해보겠다.
- Go 특유의 자료형인
channel을 이용하기 - channel은 여러 goroutine의 concurrent한 작업간 데이터 전송은 물론이고 동시적인 작업 중 데이터를 편리하게 동기화해주는 녀석이다. 따라서 동기적인 count와 유사한 기능을 내재하고있다. - golang.org/x/sync/semaphore의 Weighted를 이용하기 - Semaphore의 P를 Acquire, V를 Release로 구현해 이용할 수 있게 했다.
전체 코드는 Mutex와 동일하며 마찬가지로 다음 링크로 참고해볼 수 있다: https://play.golang.org/p/xaLE1YkAdvd
Buffered channel을 이용한 Semaphore in Go
| |
channel을 이용한 Semaphore 코드를 설명하기 위해 전체 코드 중 일부를 가져와보았다. Semaphore를 이용하기 위해 Unbuffered channel이 아닌 Buffered channel을 이용하는 이유는 다음과 같은 Unbuffered channel의 동작 방식이 Semaphore의 동작 방식과 동일하기 때문이다.
- Buffer의 크기만큼은 동시적으로 channel에 값을 넣으려는 시도가 허용됨.
- buffered channel이 꽉 찬 경우 채널에서 값을 꺼내지 않는 이상은 추가적으로 Channel에 값을 넣으려시도하는 goroutine은 Block됨.
(앞서 코드를 링크한 go playground에서 코드를 바로 실행해볼 수 있다.)
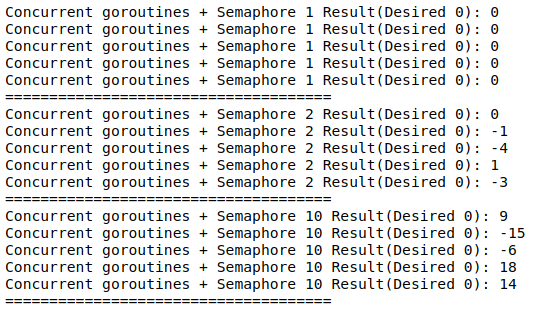
동시 접근 워커를 1개로 제한하는 Semaphore는 Binary Semaphore로서 Mutex를 이용했을 때와 유사하다고 말했듯이 thread-safe하게 count 작업이 이루어져 예상되는 값이었던 0이 출력됨을 확인할 수 있다. 하지만 동시접근이 가능한 워커가 1개 이상이 되면 thread-safe하지 않게 되고, 동시접근 워커 개수가 많아질수록 결과가 더 부정확한 경향이 있는 것으로 나타났다.
💡 Semaphore.. 그래서 언제 쓰나요?
Mutex는 thread-safe한 작업을 할 때 사용하면 되는 것 같은데 Semaphore는 개념은 알겠는데 언제 써야할 지를 잘 모르겠네요. 일정 개수만큼만 동시 접근을 허용하려는 경우가 있을까요?
Semaphore을 사용하기 좋은 케이스는 동시에 접근할 수 있는 워커 수를 제한하는 경우이고, 이는 주로 전체 작업이 늘어지는 것을 방지하고자 하는 경우에 이용된다. 많은 작업을 동시에 수행하려하면 먼저 수행될 수 있는 작업은 먼저 수행되도록 하기보다는 전체적으로 모든 작업이 늘어지게 되고 CPU나 Memory 리소스를 많이 소모하게 되고 이는 서버의 안정성에도 좋지 않다. Semaphore를 이용해 동시 접근 워커 수를 제한하고자하는 케이스는 Go의 Worker pool 패턴을 이용하는 경우나 Pipeline pattern을 이용하는 경우와 유사하다.(처음엔 Go의 모든 Concurrent pattern들을 개별적으로 구별지으려했었는데, 공부하다보니 일정한 개수의 Worker를 이용하는 Worker Pool pattern, Channel을 기반으로 작업 내역을 쪼개어 실시간 처리하는 Pipeline, 한 채널, 여러 Goroutine을 이용하는 Fan-in Fan-out pattern 등등 다들 유사하고 연관이 되어있더라.)
Semaphore로 동시 접근 Worker 수를 제한하지 않고 모든 Goroutine을 동시적으로 수행하는 경우엔 어떻게 될까?
Logical Processor 개수를 훨씬 넘는 모든 Goroutine 동시적으로 작업을 진행할 경우 아무리 Goroutine이 concurrent한 작업 수행에 뛰어난 성능을 보인다할지라도 과하게 많은 수의 Goroutine은 성능 저하를 야기하지 않을까 예상했다. 하지만 user-level thread 혹은 green level thread의 일종인 Goroutine은 OS(혹은 Kernel) thread와 달리 Context switch로 인한 penalty가 거의 없어서인지 거의 Throughput 면에서의 성능 차이가 없었다.
Kernel level thread는 OS가 스케쥴링을 담당하기 때문에 Go 프로그램이 뭐 어떻게 할 수 있는 게 아니지만 Goroutine은 프로그램이 실행되는 동안 Go 런타임이 스케쥴링을 담당한다. 같은 Kernel level thread에 속한 User level thread인 goroutine간의 switch는 cost가 거의 없다. 즉 goroutine이 많든 적든 Kernel level thread간의 context switch cost는 동일하다고 볼 수 있고, 해당 Kernel level thread에 속한 goroutine간의 context switch cost는 거의 없다.
참고: Kernel level thread에 대한 스케쥴링은 주로 Preemptive 방식을, User level thread에 대한 스케쥴링은 주로 Cooperative한 방식을 이용하지만 Goroutine은 User level thread임에도 Go 1.14 버전부터는 10ns를 기준으로 goroutine을 switch 할 수 있는 asynchronously preemptive한 스케쥴 방식을 지원한다고 한다. 하지만 Go 1.14가 릴리즈된 지 얼마되지 않아서인지, asynchorously preemptive scheduling에 대해서는 명확히 설명된 문서를 찾기 힘들었다. User level thread의 예로는 RxJava in Java, Coroutine in Kotlin, Goroutine in Golang이 있다.
하지만 Throughput 적인 측면보다는 Machine의 Resource 소모 측면에서는 모든 Goroutine이 동시적으로 수행되는 구조보다는 Semaphore을 바탕으로한 동시에 일정 개수의 워커만이 작업하는 Worker Pool 구조가 훨씬 Memory나 CPU 리소스를 적게 소모하는 듯 했다. 또한 100개의 동시 요청을 수행하는데 동일한 Throughput으로 약 10초가 걸린다고 치면, 요청당 goroutine을 생성하는 경우는 첫 번째 요청도 거의 10초가 걸린 반면 Semaphore을 이용한 경우는 먼저 온 요청은 대체로 빠르게 먼저 처리되는 경향을 보였다. 이 차이는 처음 요청을 보낸 사용자 마저 10초를 기다리게 할 것이냐, 0.1초만에 응답을 받도록 할 것이냐의 차이이다. 또한 전체 작업이 늘어지면 그 작업에 대한 메모리 점유가 지속되기에 메모리 측면에서도 비효율적이다.
Semaphore을 이용한 Go Program 2 - 이미지 크기 변환기
마침 이번에 프로젝트에서 thumbnail 생성, image 크기 변환, hashed uri 생성 작업 등을 담당하는 image processing 서버를 개발하려했는데, image를 불러오는 I/O 작업 이후의 image processing은 CPU Bound 한 작업이기 때문에 동시적으로 동작하는 Goroutine이 일정 숫자(대게 Logical Processor 개수) 이상으로는 많아져봤자 크게 효율이 없을 것이라 예상했고, 그와 관련해 간단하게 이미지 크기 변환 프로그램을 하나 만들어 테스트 해보았다.
약 2MB의 이미지에 대한 크기 변환 작업 요청이 동시에 30개 들어왔다는 가정을 했고, semaphore을 이용한 경우 동시적으로 최대 4개의 worker(goroutine)이 작업을 수행할 수 있게, concurrent를 이용한 경우는 30개의 요청 모두 동시적으로 작업을 하는 경우이다.
(코드 참고(인터넷 액세스를 하는 경우 Playground에서 동작하지는 않는듯하다): https://play.golang.org/p/Vfyw6uCOIuL)
사실 Logical Processor 8개, RAM 16GB의 개인 노트북으로는 그 차이가 많이 나지는 않아서 AWS EC2 t2.micro instance에서 성능을 테스트해봤다.
| |
놀랍게도 동시적으로 30개의 요청을 보내는 경우에 30개의 모든 goroutine이 동시에 작업을 시도할 때에는 과도한 리소스 사용으로 인해 아예 OS가 프로세스를 Kill해버렸다. 즉 Semaphore로 동시 접근 Worker 수를 제한하지 않는 경우 t2.micro 인스턴스로 돌리는 image 서버에 동시에 30개의 image resizing 요청이 들어오면 process가 죽어버린다는 말이다…!
또한 앞서 말했듯이 동시에 요청하는 사용자가 많아지더라도 Semaphore을 이용한 경우는 나중에 들어온 요청일 수록 처리가 늘어지지만, Semaphore를 통해 동시 작업을 제한하지 않는 경우는 전체 작업이 늘어진다.
이렇게 Semaphore는 동시 접근 워커 수를 제한하여 전체적인 Throughput 측면보다는 리소스 소모적인 측면과 먼저 처리될 수 있는 작업은 먼저 처리되도록 할 수 있다는 면에서 장점이 있음을 확인할 수 있었다.
마치며
Mutex나 Semaphore의 개념이나 설명과 같은 이론적인 내용은 구글링을 통해 어렵지 않게 얻을 수 있는 흔한 지식인 반면, 정확히 언제 쓰면 좋을지, 언제 쓰일 수 있을지와 같은 실용적인 내용은 찾아보기 어려웠기때문에 Go를 통해 Mutex와 Semaphore을 이용해보는 간단한 프로그램을 만들어 실습해보았다.
예제 프로그램으로서 코드를 간결하고 읽기 쉽게 깔끔하게 제공해보고자했는데, 그러기 쉽지 않았던 것 같아 아쉽다. 다음엔 기회가 되면 go의 benchmark test를 이용해보면 어떨까싶다.
참고
Goroutine과 Goroutine scheduling에 대해 - https://thegopher.tistory.com/3
화장실에 비유한 뮤텍스와 세마포어 - https://worthpreading.tistory.com/90
semaphore in Go https://medium.com/@deckarep/gos-extended-concurrency-semaphores-part-1-5eeabfa351ce
cooperative vs preemptive - https://medium.com/traveloka-engineering/cooperative-vs-preemptive-a-quest-to-maximize-concurrency-power-3b10c5a920fe
preemptive scheduling in go - https://blog.puppyloper.com/menus/Golang/articles/Goroutine과 Go scheduler