
Introduction
A few days ago, I was deploying a new version of my application to my EKS cluster at work, but I ran into an unexpected issue. The new pods couldn’t be scheduled on the existing nodes, so Karpenter scaled up additional nodes. However, these new nodes were also deemed unqualified to schedule the pods, causing Karpenter to keep scaling out nodes infinitely.
The problem was a discrepancy in allocatable memory amounts: one value was calculated by Karpenter itself, while the other was the actual value that kubelet set when joining the cluster.
Who’s Affected
This problem occurs under the following conditions:
- Karpenter
- Version < 1.6.0
RESERVED_ENISset to1
- aws-node(VPC CNI) and Pod ENI are enabled.
- A pod is scheduled that requests a certain amount of memory, which is slightly bigger than
all the remaining allocatable memory after DaemonSet pods.
(This corresponds to the blue area(
A - B) in the image below)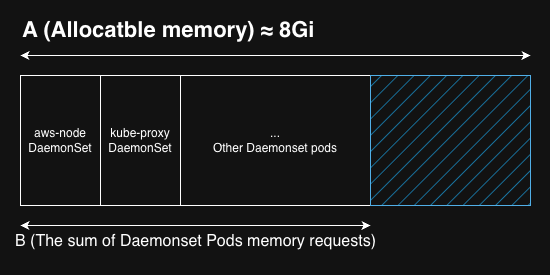
Root Cause
When Pod ENI is enabled, setting RESERVED_ENIS to 1 is recommended.
Once they are set, the maxPods value decreases compared to when Pod ENI is disabled.
For example, an m8g.large node sets its maxPods to 29 by default,
but it will set maxPods to 20 if Pod ENI is enabled.
Additionally, according to the following documentation, pods using Pod ENI don’t consume the maxPods capacity:
Branch interface capacity is additive to existing instance type limits for secondary IP addresses. Pods that use security groups are not accounted for in the max-pods formula and when you use security groups for pods you need to consider raising the max-pods value or be ok with running fewer pods than the node can actually support.
From https://docs.aws.amazon.com/eks/latest/best-practices/sgpp.html
These pods use a separate capacity called vpc.amazonaws.com/pod-eni instead.
In other words, in a cluster where Pod ENI is enabled,
the practical maximum number of pods can vary:
- When there are no pods using Pod ENI,
only the maxPods capacity is used, so only
20 podscan be scheduled. - When there are both types of pods,
up to
20 + 9 = 29 podscan be scheduled. (The 9 comes from the vpc.amazonaws.com/pod-eni.)
To understand why this matters, let’s look at how allocatable memory is calculated:
| |
The kubeReserved value is calculated as follows (Source: bootstrap.sh):
| |
Put simply, the more pods a node is configured to schedule, the less allocatable memory it will have.
Here’s where the bug occurs:
- Karpenter calculates kubeReserved based on the smaller maxPods value (20),
- while Amazon Linux calculates it based on the maximum possible value (29).
This gap leads to Karpenter overestimating an instance type’s allocatable memory and scheduling instance types that are too small. Unfortunately, these small instances fail to schedule the requested pod, which causes Karpenter to create new nodes continuously.
How to Fix It
Fortunately, this issue was fixed by aws/karpenter-provider-aws#8205 and it was merged since the release 1.6.0. Just upgrading your Karpenter to version 1.6.0 or later will prevent you from experiencing this issue.
Potential Side Effects
This issue can have severe consequences:
- Cost - New nodes are created continuously, potentially racking up hundreds or thousands of dollars within hours.
- Infrastructure saturation - In extreme cases, any infrastructure resources can become saturated, compromising infrastructure stability.
How to Reproduce The Problem
To reproduce this issue, you’ll need an EKS cluster that meets the conditions listed in the “Who’s Affected” section above, plus an isolated environment to prevent unexpected Karpenter behavior from concurrent scheduling events.
First, decide what instance type you’ll use. This process is needed to determine how much memory should be
set to reproduce node being scaled out infinitely.
I’ll use the m8g.large instance type, which has 2 vCPUs and 8 GiB of memory.
For convenience, the following instructions assume you’ll also use m8g.large.
1. Create a NodePool to support only m8g.large and m8g.xlarge instance types.
We’ll start by creating a NodePool to allow only m8g.large and m8g.xlarge, which is the smallest instance type among the ones bigger than m8g.large.
2. Disable the Pod ENI feature of VPC CNI
Before reproducing the problem for real, we’ll first confirm there’s no issue when pod ENI is not enabled.
So, please make sure ENABLE_POD_ENI of aws-node is set to false and RESERVED_ENIS of karpenter is set to 0.
RESERVED_ENIS is an environment variable, that is normally required to set 1 if you enable Pod ENI.
But, we’re disabling Pod ENI in this step, so it should be set to 0 again.
3. (Optional) Check out the maximum amount of allocatable memory in normal cases.
For accuracy, verifying the maximum amount of allocatable memory of m8g.large instances might be needed. As of November, 2025, it is 6,848,388Ki. We can calculate it in the following way.
| |
As an example, when there’s an environment as follows, the maximum memory can be allocated additionally is
6,848,388Ki (= 7,257,988Ki - 400Mi).
Here’s how I retrieved each values from the output of kubectl describe node for an empty m8g.large node.
| |
4. Confirm that a pod requesting all the remaining allocatable memory can be successfully scheduled to an empty m8g.large node.
Now, let’s check if a pod requesting the maximum memory is able to be scheduled on a new node successfully. Adding constraints to prevent it from being scheduled on any of unexpected nodes, which are not the ones from the NodePool we just created above will be helpful. For example, you can try setting a nodeSelector.
I deployed a pod requesting all the rest of the allocatable memory(6,848,388Ki), and it was successfully deployed to the empty m8g.large node. You can see that 100% of allocatable memory was allocated.
| |
5. Enable Pod ENI again.
You would remember we disabled Pod ENI and set RESERVED_ENIS set to 0 temporarily at the previous step.
Now, please enable Pod ENI and set RESERVED_ENIS to 1 again.
6. Increase the memory request of the pod by 1Ki
It’s finally time to reproduce the problem for real. We’ll deploy a new pod which requests 1Ki more memory. The actual allocatable memory of an m8g.large instance doesn’t change and it’s still 6,848,388Ki. However, karpenter will start to judge m8g.large instance will have slightly more allocatable memory, and it is qualified to schedule the new pod. As a result, Karpenter will continuously create m8g.large nodes
The following is the output when the problem was reproduced. You can see the pod keeps failing to be scheduled, and nodes are continuously being created.
| |
| |
Conclusion
This infinite node scaling issue shows what happens when two components make different assumptions about the same resource. Karpenter thought nodes would have more memory (based on maxPods=20), while the kubelet set a less allocatable memory capacity (based on the assumption that up to 29 pods can still be scheduled in the ideal case). Both are correct under their own assumptions — the assumptions just weren’t aligned.
Beyond the immediate fix of upgrading karpenter versions, this was a good reminder for me that when we enable advanced features like Pod ENI without fully understanding and verifying them, they often affect our systems in unexpected ways.