Introduction
Connections can be reset abnormarly with terminating pods when you manage istio as a service mesh solution on kubernetes.
There are a number of cases terminating pods: manually executing kubectl delete commands, rolling updates and scaling in them.
So, why are connections reset?
There can be many other reasons but I think it is the most probable terminating of istio-proxy sidecars earlier than terminating of application containers.
Prior to istio v1.12, some people used to add a preStop configuration in order to clarify for istio-proxy containers to terminates after all the active connections completes well.
| |
It is also pretty troublesome to configure preStop everytime so at the end, there were some people who used to write a mutating webhook to automatically configure proper preStop.
However, fortunately, since v1.12 EXIT_ON_ZERO_ACTIVE_CONNECTIONS feature has come out which can fix this issue.
In this post, I would handle what errors can occur when I don’t configure EXIT_ON_ZERO_ACTIVE_CONNECTIONS and check whether connections
completes safely in real when pods terminates in case I configured EXIT_ON_ZERO_ACTIVE_CONNECTIONS.
Problematic situations
- Once a pod starts being terminated,
istio-proxycontainers getSIGTERMsignals and envoy proxy doesn’t create a new connection and waits for 5 seconds. Then it terminates.- 5 second is a default value for draining duration of envoy proxies
- We expect pod to be deleted safely after all connections created before
SIGTERMcompletes right. - However, if existing connections cannot terminates within 5 seconds, it will be disconnected with errors.
In other words, requests which it takes longer to process than draining duration of envoy proxy are vulnerable .
Solution
As I just mentioned, since Istio v1.12, EXIT_ON_ZERO_ACTIVE_CONNECTIONS feature that can solve this problems has been added.
1.12 Change Notes would help. You can also refer to pilot-agent command documents.
Additionally, there also is MINIMUM_DRAIN_DURATION and it’s just a draining duration of envoy proxy which I said from above.
If I don’t enable EXIT_ON_ZERO_ACTIVE_CONNECTIONS, envoy proxy would terminates after MINIMUM_DRAIN_DURATION.
But, I can force envoy proxy to wait all the existing connection completes before its termination. In this case, I can prevent errors which happens because envoy terminates too early to complete the requests.
To apply the solution
The following is my environment for the experiment.
| Name | Description |
|---|---|
| Kubernetes | GKE 1.24.7 |
| Istio | 1.16.0 |
| Domain name | graceful-shutdown-app.jinsu.me |
| Application server deployment name | graceful-shutdown-app |
| Container image | kennethreitz/httpbin |
* In tests, I used Istio 1.16 rather than 1.12 because that’s the version I was using at the time.
kennethreitz/httpbin image is so useful when we need a simple http server.
/delay/:seconds endpoint respond after delay for :seconds after receiving a GET request.
By the endpoint, I can mimic httpbin as an application server and will be able to figure out if EXIT_ON_ZERO_ACTIVE_CONNECTIONS
works well.
First things First, let me check if errors really happen when I don’t configure EXIT_ON_ZERO_ACTIVE_CONNECTIONS and response cannot complete
within envoy’s duration seconds(5s by default) on pod termination.
| |
Let’s say graceful-shutdonw-app Deplomet is an application server.
The application server normally respond after delay for 10 seconds after getting requests.
But like the above, After pods getting SIGTERM, I got a 503 error response after a delay of about 5 seconds.
This was because envoy running in a sidecar terminated within 5 seconds and then the connection disconnected.
* More detail) The reason I got not a connection reset error but the 503 error response was because istio-ingressgateway Pod sends 503 response to http clients by itself
after it got a connection reset about the connection between istio-ingressgateway <-> graceful-shutdown-app.
You can check out more detailed logs by lowering the log level of envoy. Here is an example of the logs.
| |
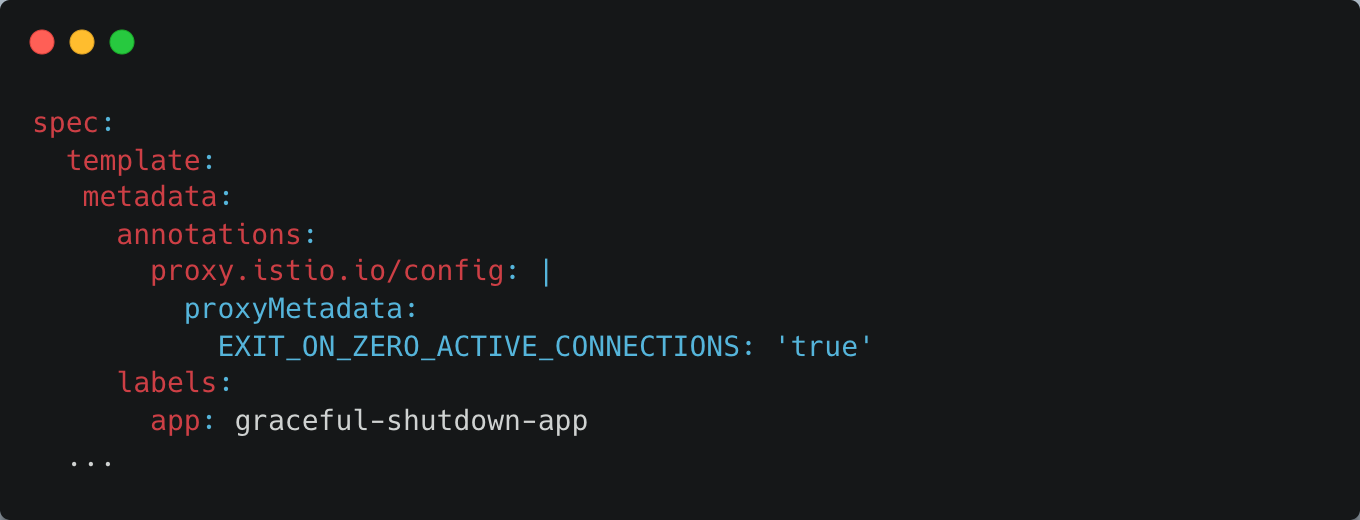
Now, finally let’s try configuring EXIT_ON_ZERO_ACTIVE_CONNECTIONS.
I annotated to pods to be created via the pod template of the Deployment.
| |
Pods which were newly created due to the update of the pod template of the Deployment had EXIT_ON_ZERO_ACTIVE_CONNECTIONS=true environment vairable, which
was injected by the istio mutating webhook.
Therefore, after getting SIGTERM, envoy terminates after waiting until there is no connection.
Like the following example, clients can always get successful responses even though there is pod termination.
| |
Caveats) If it takes longer to complete connections of an application server than the terminationGracePeriodSeconds of a pod,
you might get connection reset errors even if you enabled EXIT_ON_ZERO_ACTIVE_CONNECTIONS=true.
It’s because the container which is not terminated terminationGracePeriodSeconds after SIGTERM
will be forced to be terminated by SIGKILL.
Therefore, in such cases, you should probably set terminationGracePeriodSeconds to a higher values.
The default value is 30s for now.
(For your information, kennethreitz/httpbin image might have been developed to have 10s of max delay duration
so when you try testing an experiment like the one in the post, I think you should set terminationGracePeriodSeconds to a value lower than 10s.
In conclusion
I think EXIT_ON_ZERO_ACTIVE_CONNECTIONS feature I introduced in this post is a necessary feature but it was in face unavailable
before v1.12.
This might seem subtle but I think this must be a useful feature which can resolve inconvenience of may people.
I’d like to thank the engineers who tried to develop the feature.
Can I become a global engineer who can have a positive effect to huge open source projects? I hope so. :)